
DWH-2026: четыре зоны, открытый стек, методология вторична
Когда инженер слышит «нам нужно хранилище данных», задача редко звучит однозначно. Кто-то задыхается на боевой OLTP-базе под аналитической нагрузкой. Кто-то впервые строит отчётность и не понимает, с какого края подходить. У кого-то накопились данные из десятка систем-источников, и существующих средств уже не хватает.
У всех «хранилище». А правильный технический ответ зависит от условий задачи.
За годы работы в банках, ритейле и системной интеграции мы пришли к простой рабочей схеме: для среднего и крупного бизнеса большинство проектов хранилища сводится к четырём зонам по потоку данных поверх двух специализированных движков. Дальше разберём устройство по зонам, потом честно посмотрим, где в этой схеме остаются Инмон, Кимбалл и Data Vault, и где архитектура перестаёт подходить вовсе.
Три уровня, которые принято путать
Прежде чем спорить про архитектуру, стоит развести три разных вопроса. Их постоянно смешивают в одну кашу, и из-за этого разговоры про хранилища превращаются в спор глухих.
Парадигма хранения отвечает на вопрос «где и с какими гарантиями физически лежат данные». Сюда относятся классическое хранилище данных (DWH), озеро данных (Data Lake) и гибрид между ними - Lakehouse. Это про физику и про гарантии целостности, а не про моделирование.
Методология моделирования отвечает на вопрос «как организованы таблицы внутри слоя». Это Инмон с нормализованным корпоративным ядром, Кимбалл с фактами и измерениями, Data Vault с хабами, линками и сателлитами. Методология живёт внутри слоя хранилища, она не конкурирует с парадигмой и не заменяет её.
Инструментарий отвечает на вопрос «чем хранить и обрабатывать». Oracle, MS SQL Server, Greenplum, Spark, Trino, Iceberg, ClickHouse. Это движки и форматы.
Эти три уровня ортогональны. Можно построить ядро по Data Vault, витрины по Кимбаллу и положить всё это в Lakehouse - и в этом не будет противоречия. Раньше уровни выглядели сцепленными: выбор инструмента диктовал методологию. Реляционная СУБД с дорогим джойном на лету толкала либо к нормализации по Инмону, либо к звёздной схеме Кимбалла - потому что физика строкового движка не оставляла других вариантов. Колоночные движки эту сцепку разорвали. Сегодня инструмент больше не диктует методологию, и именно из-за этого старые методологические споры стали менее острыми, чем кажется.
Мы не изобретаем новую методологию и не предлагаем очередную «единственно верную» религию. Мы берём здравые идеи классических подходов - ориентацию на бизнес-задачу у Кимбалла, дисциплину хранения истории - и реализуем их на современном открытом стеке, который позволяет не платить за физические ограничения старых баз. Дальше - по зонам.
Архитектура: четыре зоны по потоку данных

Pre-stage и Stage - две разные схемы внутри одного формата хранения, Apache Iceberg в объектном хранилище. Trino - SQL-движок поверх обеих зон. ClickHouse - последний быстрый слой под пользовательскую нагрузку. Инструмент визуализации (Apache Superset, Metabase или эквивалент) - сверху.
Stage в этой схеме - источник истины (на схеме обозначен сплошной обводкой). Все остальные зоны можно перевыгрузить из stage. Pre-stage - копия источников, ClickHouse - копия stage. Если что-то ломается, оно восстанавливается из stage перезаливкой. Это важная инвариантность: одна зона держит истину, остальные производны от неё.
Зона 1. Pre-stage: сырьё
Pre-stage - это сырьё. Точная или почти точная реплика данных из систем-источников в формате Iceberg, без бизнес-логики, без обогащения, без человеческой оценки.
Почему именно Iceberg, а не реляционная СУБД? Несколько причин, и каждую стоит назвать отдельно.
Дешёвое горизонтально масштабируемое хранение. Iceberg-таблицы лежат как Parquet-файлы в объектном хранилище: S3, SeaweedFS, любое S3-совместимое решение. Стоимость хранения отличается от хранения тех же данных в OLTP-базе на порядок-два. Когда речь о петабайтах истории, разница экономики становится решающей: история, которую в реляционной базе пришлось бы агрессивно прореживать ради места, в объектном хранилище живёт целиком.
Эволюция схемы без миграционной паники. Источник изменил структуру таблицы: добавил колонку, убрал её, переименовал, поменял порядок, расширил тип. Iceberg трактует это как операцию только над метаданными - файлы данных не переписываются. Каждой колонке присвоен уникальный идентификатор поля, и при чтении данные сопоставляются по этому идентификатору, а не по имени или позиции. В старых файлах, где добавленной колонки нет, она читается как NULL; удалённая колонка просто игнорируется; переименование и смена порядка не трогают данные вообще, потому что идентификатор остаётся прежним. Документация Iceberg прямо называет добавление, удаление, переименование, переупорядочивание и расширение типа безопасными изменениями без побочных эффектов. Чего она не гарантирует - сужение типа (поддерживается только расширение) и семантический слом, когда смысл колонки поменялся, а имя и идентификатор остались: это уже не про формат, а про моделирование на нашей стороне. Но даже с этой оговоркой разница с реляционной базой огромная: там то же изменение вылилось бы в координированную миграцию миллиардов строк с окном простоя.
Метаданные и данные физически разделены. Каталог Iceberg-таблицы (снимки, манифесты, версии схемы) живёт отдельно от Parquet-файлов с фактическими данными. Каталог можно повредить, потерять, восстановить из бэкапа - сами Parquet никуда не денутся. У файлов реляционной СУБД таких гарантий нет: повреждение служебной структуры тянет за собой потерю данных целиком.
Формат портабелен. Parquet читается любым движком, который понимает формат: DuckDB, Trino, Spark, Pandas, ClickHouse. Нет привязки к версии конкретного коммерческого движка, нет лицензионных ограничений на чтение собственных данных. К этому тезису вернёмся в разделе про стек - это центральная мысль всей архитектуры.
Нет привязки к узкому специалисту. Iceberg обслуживается через Trino, и инженер, умеющий работать с Trino, переносится между проектами без переучивания. Сравните с наймом отдельного DBA под Greenplum или Vertica: ставка такого человека сегодня заметно выше, чем универсального дата-инженера, и людей таких на рынке меньше.
И пара организационных причин, про которые часто забывают.
Pre-stage снимает нагрузку с команд продуктов-источников. Вместо привычного «разработчик 1С, сделай нам выгрузку под аналитическую задачу» данные уже лежат у нас. Команды-источники заняты своим продуктом и не отвлекаются на наши запросы.
Захват изменений (CDC) под нашим контролем. Что обновлять, что добавлять, как обрабатывать удаления, какой приоритет у разных таблиц - решаем мы. Источник просто отдаёт изменения, дальнейший маршрут наш. Это убирает недетерминированность, которая обычно сидит в чужих выгрузках.
Аналитики экспериментируют на pre-stage, а не на боевой OLTP. Возможно, главная организационная польза. Любой DBA знает цену того момента, когда любопытный аналитик запустил SELECT * без LIMIT на учётной системе в час пик. Во что превращается, казалось бы, рутинная операция на боевой базе, я разбирал в отдельном постмортеме. Pre-stage даёт ту же глубину доступа к данным, но боевую базу не трогает.
С чем работаем в pre-stage? С Trino. Его роль - независимый SQL-движок с горизонтально масштабируемым пулом рабочих узлов. Один координатор плюс N воркеров, число воркеров подбирается под нагрузку. Запросы аналитика на терабайтных таблицах из Iceberg исполняются в разы быстрее и при этом не нагружают боевые системы.
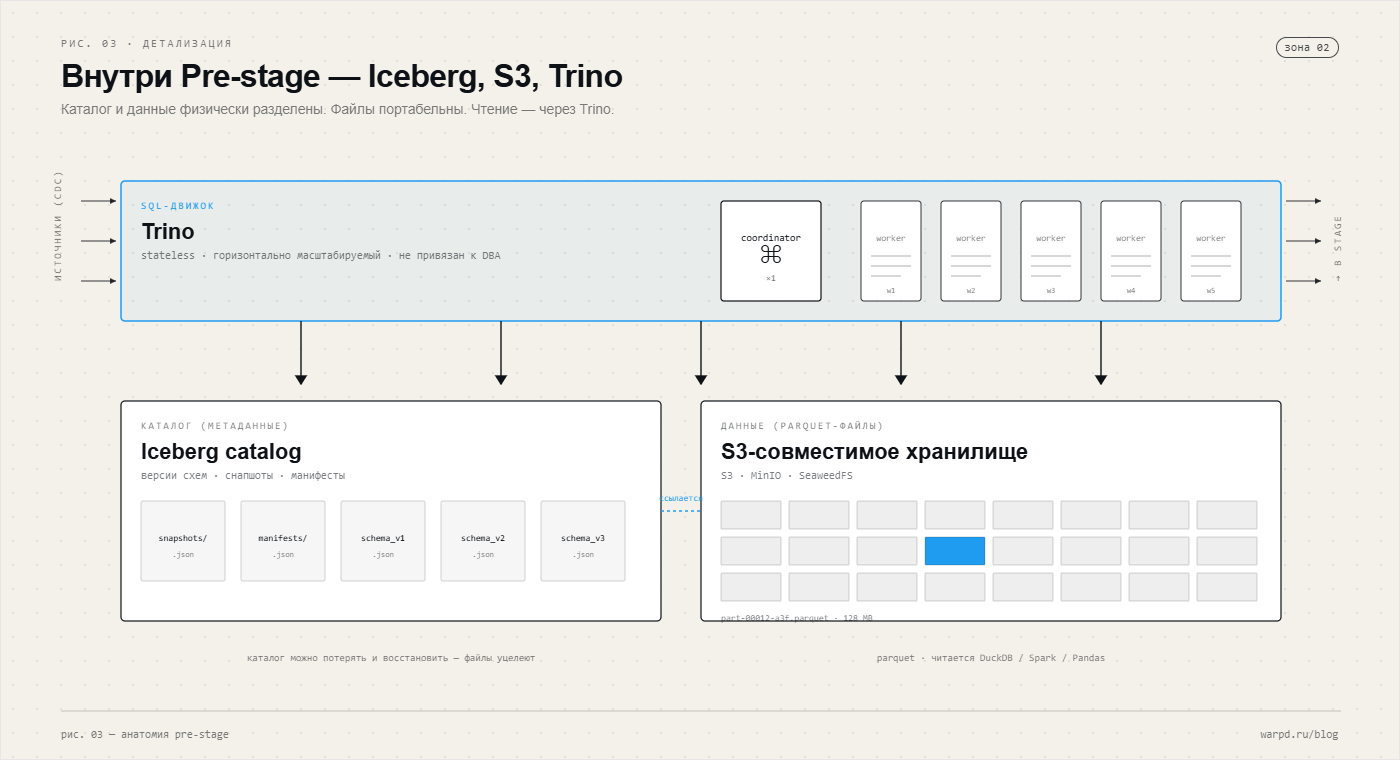
На схеме - как именно Trino работает поверх Lakehouse. Координатор принимает SQL-запрос, читает каталог Iceberg (снимки, манифесты, версии схемы), чтобы понять, какие Parquet-файлы и в каком разрезе нужны, а затем раздаёт чтение параллельно по пулу воркеров. Воркеры читают Parquet из объектного хранилища напрямую, минуя координатор - поэтому пропускная способность растёт почти линейно с числом воркеров. Воркеры не хранят состояние, их можно добавлять и убирать на лету. Это та же модель и для pre-stage, и для stage: меняется только содержимое схем.
Одна оговорка, специфичная для Trino. Линейность по воркерам держится не сама по себе, а за счёт пушдауна: Trino проталкивает фильтры, выборку нужных колонок и отсечение партиций внутрь чтения Iceberg, поэтому воркеры читают только относящиеся к запросу Parquet-файлы и колонки, а не таблицу целиком. Если таблица не разложена под это (нет вменяемого партиционирования, файлы слишком мелкие или слишком крупные), пушдаун вырождается, воркеры начинают читать всё подряд, и наращивание их числа перестаёт спасать. Это не магия движка, а то, что закладывают на этапе проектирования stage.
Зона 2. Stage: трансформация под бизнес-задачу
Здесь начинается самая интересная инженерная работа.
Сразу про терминологию, потому что на ней спотыкаются чаще всего. То, что мы зовём Stage, в общепринятом словаре ближе к ядру или core/silver-слою, а не к транзитному staging. Классический staging - это временный буфер загрузки: данные падают в него на время ETL и затираются на следующем прогоне, истории там нет. Наш Stage - противоположность: он держит бизнес-логику, историю изменений и является источником истины. Откуда взялись сами названия pre-stage и stage? Они перенесены из модели разработки программного обеспечения, где изменения проходят через промежуточную среду (staging) перед выкаткой в боевую. Наш поток данных напоминает ту же модель продвижения: сырьё попадает в pre-stage, проверяется и готовится, а затем продвигается в stage как версия, с которой уже работают потребители. Аналогия нестрогая, но именно она закрепила эти имена в наших проектах. Читать stage нужно как «ядро», не как «landing».
Stage - результат труда аналитика и инженера над конкретной задачей бизнеса. Большие денормализованные широкие таблицы, специально подготовленные под определённый набор дашбордов или продуктовых сценариев. Со всей бизнес-логикой, со всей историей изменений (SCD2), со всем обогащением справочниками.
Физически stage живёт в том же Iceberg, но в отдельной схеме (или пространстве имён каталога, если терминологически точнее). Это не отдельная инфраструктура, а вторая зона того же Lakehouse, со своими правилами и циклами обновления.
Как наполняется? Trino-запросами, которые формирует аналитик под задачу. Пример. Бизнесу нужна аналитика продаж по магазинам. Аналитик пишет запрос, который берёт кассовые ленты из pre-stage, соединяет с товарным справочником, со справочником магазинов, со справочником промоакций, со справочником сегментации клиентов - и формирует одну широкую таблицу «Продажи по магазинам». Эта таблица сохраняется в stage и становится источником истины для соответствующего набора дашбордов.
Планировщик ETL (Apache Airflow с оператором Trino, Apache SeaTunnel, Dagster или любая другая система оркестрации - конкретный выбор обычно зависит от того, что уже стоит у клиента) запускает запрос периодически. Раз в сутки, раз в час, раз в минуту - в зависимости от требований к свежести.
Тонкий момент, который часто упускают. Что хранится в широкой таблице stage?
Не текущее состояние справочника. Состояние на момент совершения транзакции. Если вчера товар назывался «Хлеб», а сегодня его в справочнике переименовали в «Хлеб ржаной», запись о вчерашней продаже в stage останется с «Хлеб», ровно так, как было фактически. Дополнительно хранится ключ товара, который позволяет при необходимости подтянуть актуальное название.
Это не ошибка, а сознательное решение. Stage хранит факты, а не значения справочников в их последней редакции. Отчёт «как было на момент продажи» строится без всяких пересборок. Отчёт «по текущей классификации» решается отдельным справочником актуальных значений, который соединяется при выгрузке. Ретроспективных пересборок широкой таблицы при изменении справочника не требуется - и это снимает целый класс ночных перерасчётов, которыми живут классические витрины.
Логически мы здесь в парадигме Кимбалла. Идём от бизнес-задачи снизу вверх, строим витрину под конкретную нужду, аккуратно ведём историю изменений и разделяем факты и измерения как логические сущности. Это здравый смысл, который никуда не делся.
Но физическую реализацию Кимбалла мы не используем. Звёздная схема (отдельные таблицы фактов и измерений с джойном на лету) была вылеплена под строковые реляционные хранилища - Oracle, Teradata, MS SQL Server до колоночных индексов, - где соединение на лету было дешевле, чем хранить дубли. На колоночных движках выигрыш звёздной схемы либо отсутствует, либо отрицательный. Поэтому stage отдаёт уже широкие денормализованные таблицы, и джойн на лету при чтении дашборда не делается вообще. Точнее всего сказать так: Кимбалл как способ думать жив, Кимбалл как физический паттерн устарел.
Про Data Vault без прикрас. Двойная работа в нём - это буквально два больших прохода. Сначала огромный объём запросов превращает сырьё в полную декомпозицию: хабы, линки, сателлиты. Потом ещё один огромный объём запросов собирает из этой декомпозиции витрины обратно в широкие таблицы. А пользуется аналитика в основном именно витринами. Возникает резонный вопрос: зачем тогда двойная работа?
Практика отвечает так. К сырому уровню обращаются единичные запросы бизнеса. Но для разовой задачи по трудоёмкости нет разницы, идти в декомпозицию Data Vault или напрямую в сырьё - декомпозиция здесь ничего не экономит, скорее наоборот, собрать ответ из россыпи хабов и сателлитов сложнее, чем из сырой таблицы. А если бизнесу нужен систематический доступ к каким-то данным, мы просто строим под них ещё одну широкую таблицу stage. Получается, в среднем сегменте слой хабов, линков и сателлитов не приближает к ответу на бизнес-вопрос ни в массовом случае, ни в разовом. Плюс к этому десяток источников разрастается в две-три сотни физических таблиц, и порог входа для нового инженера высокий.
И при этом - не «наша архитектура лучше методологии». Методология ортогональна зонам, вопрос всегда «что уместно при этих условиях». Там, где регулятор требует полный журнал всех изменений данных - банки под надзором ЦБ, страховые с многолетней историей полисов, оборот драгметаллов под пробирным надзором, - хабы, линки и сателлиты Data Vault решают задачу системнее, и там это правильный каркас. В среднем сегменте это двойная работа без отдачи. На том и стоим.
Почему stage - самый ценный слой хранилища? В ней материализована вся работа аналитика и инженера: бизнес-логика обогащения, правила отнесения к сегментам, история изменений, расчёт промежуточных метрик. ClickHouse дальше получит только копии этих таблиц. Если ClickHouse упадёт и потребует пересоздания - не критично, stage цел, перевыгрузим. А если потеряется stage - это потеря исторических срезов, правил расчёта, месяцев работы аналитической команды. Поэтому stage обкладывается всем, что положено: полные снимки Iceberg, откат к любой исторической версии (time-travel), репликация в другой регион при необходимости.
Зона 3. ClickHouse: витрина выдачи
ClickHouse - копия stage-таблиц, специально подготовленная под обслуживание дашбордов.
Зачем нужен отдельный движок поверх Iceberg, если Trino уже умеет читать stage? Инженерная причина простая: Trino - универсальный SQL-движок для трансформаций, ClickHouse - специализированный колоночный движок под аналитическую выдачу. Под нагрузкой, где сотни конкурентных пользователей одновременно тыкают дашборды и ждут отклика за миллисекунды, ClickHouse выигрывает с большим отрывом. Trino при такой нагрузке начнёт упираться в координатор и в очередь воркеров - он не для этого создан.
Как наполняется? Stage-таблицы периодически копируются в ClickHouse. Под это есть специальный тип таблицы ReplacingMergeTree: он естественным образом дедуплицирует строки по ключу при фоновом слиянии. Загружаем партию обновлений, движок сам разбирается, какие строки актуальны.
Принципиально: ClickHouse не источник истины. Это быстрая витрина-копия. Что снимает с него часть инженерных требований - бэкап, сохранность, восстановление становятся проще, потому что в случае проблемы данные перевыгружаются из stage. Стратегия восстановления простая: снести и перелить.
Про моду последних месяцев. Появилось много шума, что ClickHouse 25.x умеет читать Iceberg напрямую, и поэтому Trino становится «опциональным». Реальность скромнее: чтение Iceberg из ClickHouse работает для базовых случаев V1/V2, но equality deletes не поддерживаются (а это базовая возможность V2 для сценариев захвата изменений), запись помечена как экспериментальная, распределённого чтения через пул воркеров нет. Как замена Trino в проде это пока не идёт. Для разовых запросов аналитика «посмотреть, что лежит в stage» - вариант рабочий. Для основного контура - нет.
Зона 4. Визуализация
Apache Superset, Metabase, Power BI Report Server (там, где он лицензионно доступен) или любой другой инструмент, привычный команде. Дашборды строятся на широких таблицах ClickHouse без джойнов на лету, поэтому работают быстро.
С инструментом визуализации обычно меньше всего архитектурных дискуссий: выбирается тот, что уже есть в компании или с которым удобнее аналитической команде. Архитектурно значимое решение здесь уже принято раньше - в stage и ClickHouse, - а не на этом слое.
Технологический стек: почему Iceberg + Trino + ClickHouse
Главный тезис всей архитектуры - независимость от вендора. Не четыре зоны сами по себе, а то, на чём они стоят.
Сравним два мира.
Старый мир: Oracle, MS SQL Server, Greenplum, Vertica. Данные лежат во внутреннем формате движка. Чтобы их прочитать, нужен этот конкретный движок и его лицензия. Миграция данных между движками - отдельный болезненный проект. Нужны узкие специалисты под конкретную СУБД, их ставка высокая, на рынке их мало. Стоимость владения растёт вместе с объёмом данных, а не вместе с пользой от них.
Наш мир: открытый формат. Данные лежат как Parquet в объектном хранилище, метаданные - в каталоге Iceberg. Эти файлы прочитает любой движок, который понимает формат: Trino, Spark, DuckDB, ClickHouse, Pandas. Нет привязки к проприетарному формату хранения, нет лицензии на чтение собственных данных, движок можно сменить без миграции данных - меняется только то, что читает те же файлы.
Здесь важно быть честным и не продать иллюзию. Привязки к формату нет, но операционная цена есть, и её надо называть вслух. Trino требует эксплуатационной экспертизы: память воркеров, тайм-ауты запросов, мониторинг, обновления между мажорными версиями. Каталог Iceberg - это отдельное архитектурное решение со своими компромиссами. Чтение Iceberg из ClickHouse, как сказано выше, ограничено. Открытый стек убирает привязку к вендору, но не убирает необходимость в людях, которые умеют его эксплуатировать. Это другой тип сложности, не нулевой.
Роли компонентов коротко:
- Iceberg - хранение с гарантиями целостности, снимками и эволюцией схемы. Это парадигма Lakehouse в конкретной реализации.
- Trino - SQL-движок для тяжёлых трансформаций и работы со stage. Масштабируется горизонтально, операционно проще Spark, не требует экспертизы JVM-стека.
- ClickHouse - специализированная витрина для сверхбыстрой выдачи в дашборды. Не источник истины, а копия stage.
Почему именно Trino, а не Spark или DuckDB. Spark тяжёлый и требует отдельной экспертизы JVM-стека. DuckDB одноузловой и не масштабируется на распределённую нагрузку. Trino даёт баланс масштабируемости и операционной простоты для среднего сегмента - это не догма, а инженерный компромисс под конкретный класс задач.
Где это похоже на известные паттерны
Чтобы не делать вид, будто схема придумана с нуля. Похожие идеи в индустрии называли по-разному. Databricks упаковали это как Medallion architecture: bronze (сырьё) → silver (очищенное и обогащённое) → gold (готовые витрины). Сообщество dbt говорит про modern data stack: sources → staging → intermediate → marts. Логически это близко к нашему pre-stage / stage / ClickHouse-витрина.
Чем отличается наша реализация:
Во-первых, явный слой выдачи на ClickHouse как отдельный движок. Medallion обычно остаётся внутри одной платформы - всё в Spark или всё в Databricks. Мы выносим финальную витрину в специализированный движок, потому что для пользовательской нагрузки колоночный движок с миллисекундным откликом качественно лучше универсального SQL-движка.
Во-вторых, обязательная дисциплина истории изменений (SCD2) в stage. Многие команды забывают про неё в Medallion-стеке и через год получают отчёты, которые «вдруг перестали биться» с историческими данными. Мы выносим SCD2 в обязательные требования к stage. Это главное наследие Кимбалла, которое мы сохраняем.
В-третьих, независимость от вендора как осознанный приоритет, а не побочный эффект. Открытый формат хранения для нас - не «приятно иметь», а условие, от которого мы не отказываемся.
Когда эта архитектура не подходит
Самый важный раздел. Архитектурная статья без честного «когда не подходит» - реклама, а не инженерный текст. Ниже - сценарии, где четыре зоны избыточны или хуже альтернатив.
Один источник, до сотни пользователей, нет требований к реальному времени. Если данные в одной учётной системе (MS SQL Server или Oracle), аналитиков пара десятков, и нет требований к отклику за доли секунды - проще не строить отдельное хранилище вообще. Колоночные индексы (Columnstore в SQL Server, In-Memory Column Store в Oracle), материализованные представления, выделенная схема analytics с агрегатными таблицами, обновляемая ночными заданиями. Этот набор закрывает большую часть потребностей среднего бизнеса без миграции в новый стек и без полугода интеграционных работ. Окупаемость такой работы кратно выше, чем строить параллельное хранилище.
Стартап до 5 ТБ с одним аналитиком. Локальный DuckDB поверх Parquet-файлов в объектном хранилище закрывает кейс целиком. Без кластера Trino, без серверов ClickHouse. Один аналитик с DuckDB и Jupyter обрабатывает терабайты и экспортирует в дашборд. Развёртывание четырёх зон тут убьёт скорость итераций. Это не то же самое, что промышленный кластер - не путайте.
Реальное время с задержкой в миллисекунды. Биржа, рекламная аналитика, телеметрия с десятками тысяч событий в секунду, где задержка между записью и доступностью в дашборде должна быть меньше секунды. Stage в Iceberg добавляет минуты задержки на запись и фиксацию. Здесь правильнее чистый ClickHouse с прямым потоком из Kafka, а Iceberg-зона работает только как холодный архив параллельно горячему контуру.
Очень крупное предприятие с регуляторным журналом изменений. Банки под надзором ЦБ, страховые с многолетней историей полисов и претензий, оборот драгметаллов под пробирным надзором. Там Data Vault системнее: хабы, линки и сателлиты решают задачу полного аудита изменений, которую в четырёх зонах пришлось бы изобретать в обход. Это ровно тот случай, когда методология внутри слоя выбирается не наша.
Нет команды на эксплуатацию Trino. Trino требует операционной экспертизы. Если в команде нет ни одного человека, готового заниматься его эксплуатацией, проще остаться на текущем стеке, чем взять в работу систему, которую некому поддерживать. Архитектура, которую некому обслуживать, хуже простой архитектуры, которую обслуживать умеют.
Команда с инвестицией в Spark или Databricks. Если уже есть кластер Spark с хорошей эксплуатацией и квалифицированной командой, не нужно его выкидывать ради Trino. Spark тоже пишет в Iceberg, связка Spark + Iceberg работает, и переход на Trino добавит организационных трений без существенного выигрыша.
Отдельно про границу самого подхода с историей. Состояние на момент транзакции закрывает фактовую аналитику. Но есть редкий класс отчётности - состояние связи самой по себе, без привязки к факту. Например, «под какой структурой числился магазин в марте» для оргструктуры, аренды, штатного расписания, где транзакции в этот период могло не быть вообще. Если у бизнеса есть регулярная потребность в такой отчётности, само изменение связи моделируется как факт - отдельная таблица изменений «магазин сменил структуру тогда-то», и состояние на любую дату восстанавливается из неё. По сути это та же история изменений SCD2, только выраженная как факт-изменение, а не как отдельный справочник с интервалами действия: концепция остаётся, меняется лишь представление. Разовые вопросы такого рода закрываются прямым запросом к хранилищу. Это спектр отчётности, который решается гибко, а не пробел в схеме - но знать про него надо заранее.
Резюме
Шпаргалка для самопроверки, какой паттерн уместен в каком сценарии:
-
Аналитический слой внутри существующей OLTP - данные в одной системе, пользователей до сотни, нет требований к реальному времени. Большая часть среднего бизнеса в России - именно здесь. Колоночные индексы, материализованные представления, выделенная схема с агрегатными таблицами. Сроки - недели, не месяцы.
-
Четыре зоны на Iceberg + Trino + ClickHouse - несколько источников, или нагрузка выше сотни пользователей, или аналитика, близкая к реальному времени. Наш средний и крупный тир, типичный проект на 3-6 месяцев.
-
Четыре зоны плюс дополнительные движки (Spark, dbt) - крупный сегмент, десятки терабайт, мультидвижковые сценарии.
-
Data Vault - очень крупные предприятия с регуляторными требованиями к журналу изменений. В среднем сегменте избыточен.
-
DuckDB и Parquet локально - стартап до 5 ТБ с одним аналитиком. Не путать с промышленным кластером.
Если свести всё к одной мысли: методология моделирования - это локальный выбор внутри слоя stage, а не каркас всего хранилища. Каркас задаёт поток данных по зонам и открытый формат хранения. Кимбалл мы берём как способ думать, открытый стек - как способ хранить, и никакой привязки к вендору. А что класть внутрь stage по методологии - вопрос конкретных условий задачи, а не идеологии.
Чего мы стараемся не делать - продавать клиенту Lakehouse там, где задача решается на его существующей базе. Или продавать звёздную схему туда, где работает денормализованная stage. Или строить четыре зоны для бизнеса, у которого один источник и десять читателей. Архитектура должна соответствовать масштабу задачи. Это, как сказали бы старые DBA, и есть здравый смысл.
Если у вас стоит вопрос «что строить» - расскажите про ваш кейс. Поговорим, что подходит именно вам.

Основатель WARP.D. 30 лет в отрасли - от администрирования SQL Server до архитектуры data-платформ на открытом стеке. Банки, инвестиционные компании, федеральный ритейл.