
Идеальный failover в AlwaysOn AG: инцидент на 7,5 часов
Воскресное утро, 06:50. Дежурный DBA получает алерт: автоматический failover группы доступности AG-Production с узла srv-prod-01 на вторичную реплику. SQL Server отработал безупречно. Четыре секунды на переключение роли, listener IP перебиндился, новая primary в SYNCHRONIZED. Microsoft бы поставил пятёрку.
Ручной failback завершили в 14:24.
Семь с половиной часов между двумя точками. Бизнес-системы при этом «вроде бы» работали. Алерты, кстати, сыпались - по failed-джобам. Только шли они в группу поддержки бизнес-систем, как и положено по их routing-конфигурации. Корни этих failed-джобов уходили не в бизнес-логику, а в недоехавшую обвязку AG - починить которую могла только DBA-команда. А DBA-команда таких алертов не получала: бизнес-джобы у неё в routing’е не значились. Все думали, что проблема у соседа.

Именно эта связка - тихий частично-работающий режим плюс настроенный по логике, но не сработавший в данной ситуации alerting - самое коварное в подобных инцидентах. Реального полного простоя не было. Был частично функциональный режим, в котором часть подсистем продолжала работу - но не так, как должна. И главная опасность здесь не в том, что какой-то пользователь наткнётся на сбойную джобу или плановый отчёт покажет странную цифру. Главная опасность - в данных.
За 7,5 часов ETL-джобы, привязанные к failover’нувшей primary, либо не отрабатывали вовсе, либо отрабатывали на неконсистентном source-state. Смежные системы - те, в которые шли регулярные выгрузки и из которых шли загрузки - могли получить пропущенные batch’и, частичные данные или данные, рассогласованные с источником. От этого до полной data inconsistency между корпоративными системами - буквально несколько срабатываний ETL.
И эту рассогласованность штатный мониторинг ловит не всегда. Часть её всплывает только при reconciliation или при сведении отчётности в конце периода. Восстановление консистентности - отдельная задача: дни ручного разбора, в худшем случае - откат смежных систем с резервной копии. Пользователь, наткнувшийся на сбойную джобу - это самое видимое из последствий. Самое опасное скрыто глубже: оно в данных, которые внешне выглядят нормально, но не сходятся между системами.
Команде сильно повезло: это было воскресенье, основные бизнес-операции не велись. В рабочий день дефекты обвязки проявились бы быстрее и громче. Такие инциденты - подарок для команды: можно разобрать всё спокойно, без управленческого давления при реальном простое, и превратить ситуацию в хороший и бесплатный урок. Тем более если речь идёт об инфраструктуре, где в обычный день цена ошибки измеряется не репутацией, а напрямую деньгами.
В этой статье я разберу настоящий инцидент (детали обезличены) и покажу:
- Четыре независимых триггера failover, которые DBA путают друг с другом
- Почему агрессивно увеличенный
SameSubnetThreshold=20не спас от потери кворума - Как обвязка AG превращает «failover за 30 секунд» в часы потенциальной рассогласованности данных между корпоративными системами
- Почему алерты сыпались, но никто не реагировал - и при чём здесь дизайн cross-team alert routing’а
- Что меняет Contained AG в SQL Server 2022/2025 и какие новые failure modes он создаёт
- Когда автоматический failover оправдан, а когда вреден
Хронология инцидента
| Время | Событие |
|---|---|
| ~04:55 | Сетевая нестабильность - первые признаки потери подключения |
| 06:33 | DNS и контроллер домена недоступны с srv-prod-01 (Event ID 1014, 5719) |
| 06:50 | WSFC потерял кворум - FSW недоступен (ошибка 53) |
| 06:50 | ClusSvc аварийно завершён, automatic failover на secondary |
| 14:24 | Ручной failback на srv-prod-01, сервис восстановлен |
Внешне всё работает как должно. Алерт пришёл, кластер отреагировал, AG переехал. Обратите внимание на интервал между 06:50 и 14:24 - семь часов и тридцать четыре минуты, в течение которых AG жил на secondary, а бизнес-функции исполнялись «вроде бы» нормально - с тихими дефектами, которые в выходной день никто не успел заметить.
Почему «вроде бы»? Сейчас разберёмся.
Четыре триггера failover, которые путают друг с другом
Среди опытных DBA - и тем более среди инженеров, которые не каждый день копаются в WSFC - живёт упрощённое представление: «AlwaysOn failover’ится, когда primary упала». На практике AlwaysOn реагирует не на одно событие, а на четыре независимых класса:
| Триггер | Что мониторит | Как тюнить |
|---|---|---|
| WSFC heartbeat | Видят ли ноды друг друга по сети | SameSubnet*, CrossSubnet* |
| Quorum loss | Достаточно ли голосов чтобы кластер продолжал работать | Дизайн witness, NodeWeight |
| AG health check | SQL Server отвечает в нормальные сроки | HEALTH_CHECK_TIMEOUT, FAILURE_CONDITION_LEVEL |
| Resource failure | AG-ресурс жив на текущем узле | DelayRestarting, RestartThreshold |
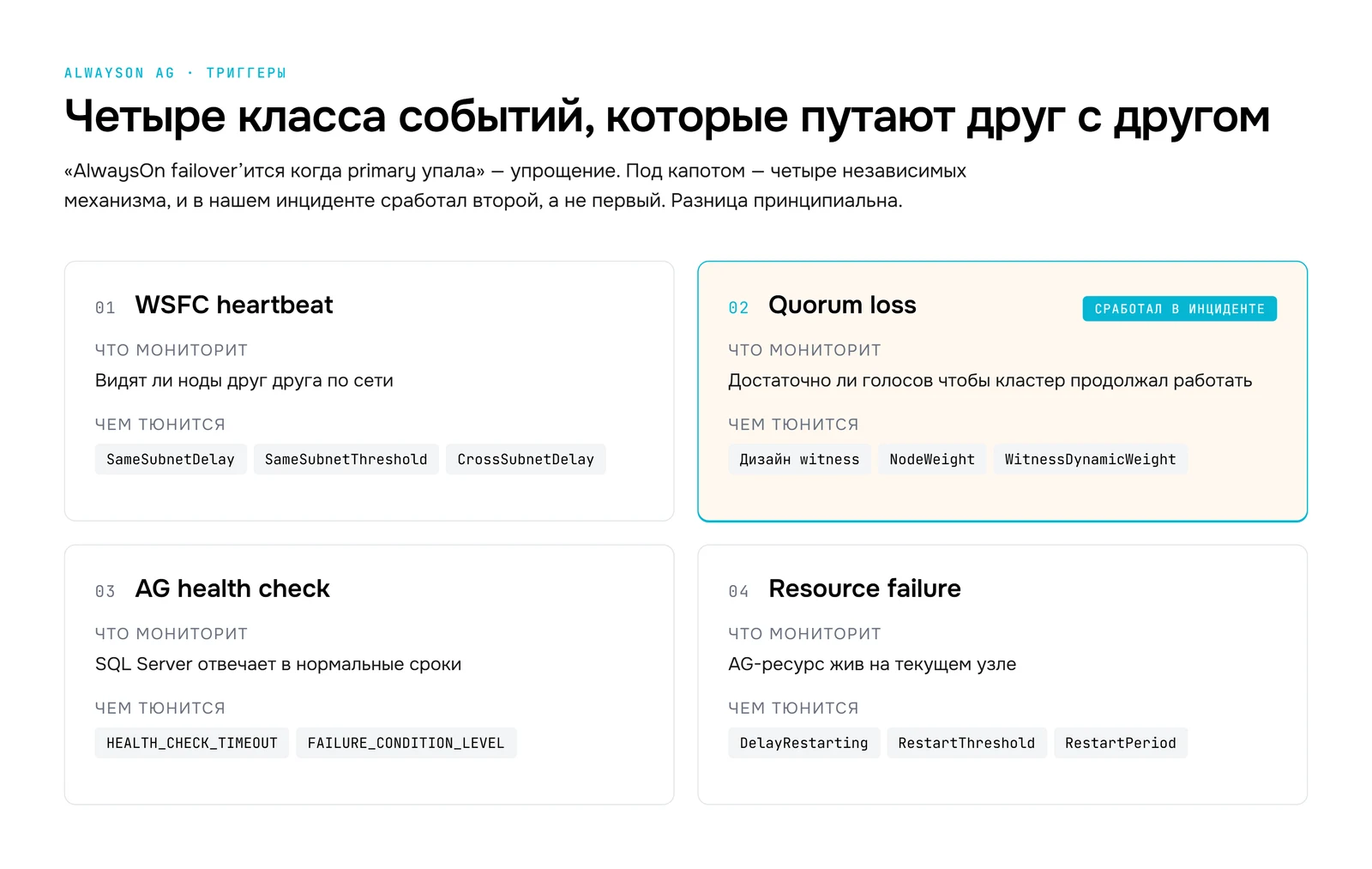
В нашем инциденте сработал второй - quorum loss. Не первый. Между ними принципиальная разница.
WSFC heartbeat между нодами в момент инцидента шёл нормально. Связь 10.0.10.10 ↔ 10.0.10.20 была, threshold=20 (DBA уже подкручивал, как опытный человек), пропуски были, но не превышали порог. А вот FSW - File Share Witness - пропал. И в этот момент srv-prod-01 оказался в quorum minority: одна нода кластера + потерянный witness = меньше половины голосов. WSFC вынужден завершить ClusSvc на этой ноде, чтобы не допустить split-brain.
Это не failover из-за «нода упала». Это failover из-за «кворум распался, и winner-сторона забрала роль primary». Совершенно другой класс события.
Почему SameSubnetThreshold=20 не помог
Подкрутка heartbeat-threshold - первое, что делает зрелый DBA, когда видит false-positive failover’ы от сетевых blip’ов. В нашем кейсе ровно этим и занимались:
SameSubnetDelay = 1000 ms (default)
SameSubnetThreshold = 20 (default = 5)Кластер ждал двадцать секунд пропавших heartbeat прежде чем считать ноду недоступной. Для рядовых сетевых glitch’ов работает. В нашем сценарии - не сработало, потому что причина была другая.
FSW сидел на отдельном файловом сервере, доступном по той же сетевой инфраструктуре, что и одна из нод кластера. Когда сеть просела на srv-prod-01, нода продолжала видеть srv-prod-02 напрямую (heartbeat OK), но потеряла FSW. Кворум распался независимо от heartbeat-настроек. ClusSvc на потерпевшей ноде упал, AG переехал.
Отсюда правило, которое часто упускают:
Heartbeat threshold защищает от network blip’ов между нодами кластера. От потери witness он не защищает.
В нашем инциденте witness был single point of failure в quorum design. И это не вопрос настроек кластера, а вопрос дизайна инфраструктуры до того, как кластер был построен.
Что должно было быть сделано иначе
Корневая ошибка - witness располагался в той же сетевой зоне, что и одна из нод кластера. Корректный witness в 2026 живёт в третьей независимой сетевой зоне, не зависящей от локальной сети, на которой стоят primary и secondary. Native-варианты Microsoft, в порядке от наиболее реалистичного для on-prem RU-клиента к менее:
- File Share Witness в третьем сетевом сегменте - не «третий датацентр» (которого часто нет), а отдельный VLAN с независимой маршрутизацией, отдельным контроллером домена или routing’ом наружу. Витнес сидит на файловом сервере в этом сегменте. Просадка локальной сети основного кластера не валит witness, потому что он маршрутизируется иначе. Самый практичный вариант для большинства on-prem-сценариев.
- Disk Witness через shared SAN/iSCSI. Если у компании уже есть enterprise-storage (NetApp, Pure, IBM, HPE 3PAR), и LUN можно презентовать всем нодам кластера - это самый надёжный witness из native-вариантов. Не зависит от сети вообще, живёт на отдельной storage-фабрике. В финсекторе и крупном ритейле часто доступен.
- Cloud Witness через Azure Blob Storage - native-фича Microsoft (Windows Server 2016+). Использует HTTPS и Storage Account Key, домен не требуется (это и есть его главное преимущество перед FSW). Минус для RU-клиентов в 2026: Azure из России практически недоступен из-за санкционных ограничений, поэтому в чистом виде применим редко - в основном у компаний с международной инфраструктурой.
Что я не рекомендую в качестве production-witness:
- «S3-compatible witness» через VK Cloud / Yandex Object Storage - community-tools, имитирующие Cloud Witness protocol поверх S3-совместимого хранилища. Microsoft эту схему не поддерживает официально. Для prod в финсекторе - не путь.
- Самописный скрипт-переключатель между двумя FSW - native-фичи «два FSW и кластер сам между ними переключается» в Windows Server нет. То что иногда называют «двойным witness» - это самописная обвязка через cron +
Set-ClusterQuorum -FileShareWitness, которая сама становится точкой отказа. Допустимо как временное решение, не как прод-архитектура.

Withess можно поменять без рестарта кластера - команда Set-ClusterQuorum -FileShareWitness \\new-server\quorum работает на живом кластере. Так что миграция со «слабого» witness на правильный - не требует окна обслуживания.
Выбор witness - только половина истории. Вторая половина - правильное распределение NodeWeight’ов:
# Если witness падает, кластер с двумя нодами должен продолжать работу
# при условии что обе ноды видят друг друга
(Get-ClusterNode).NodeWeight = 1
(Get-ClusterQuorum).WitnessDynamicWeight = 0Не подходит для всех топологий, но в 2-узловом сценарии с witness в той же сети что и одна из нод - часто спасает от ложных failover’ов при потере witness.
Семь с половиной часов: куда они делись
Вернёмся к главной аномалии нашего инцидента. AG переехал в 06:50, ручной failback - в 14:24. Между этими точками сервис не работал, хотя AG-кластер технически работал. Что произошло?
В AG переехало только содержимое user-databases. Всё остальное - instance-level - осталось на старой primary либо «полу-работало» на новой:
- SQL Agent Jobs в
msdb: на secondary либо отсутствовали, либо были устаревшие копии. Регулярные ETL-процессы, которые крутятся каждый час - не запустились. Бизнес-аналитика, которая ждёт ночные джобы - получила пустые витрины утром. - CDC (Change Data Capture): capture/cleanup-джобы привязаны к instance. После failover capture не идёт,
log_reuse_wait_descуходит вREPLICATION, лог пухнет. Параллельная Kafka, забирающая изменения через Debezium, не получает событий. - Linked Servers к смежным базам: на secondary не настроены. Кросс-серверные запросы валятся.
- Logins через стандартный pre-2022 механизм: SID на secondary не совпадают с primary. Orphaned users. Часть приложений теряет authentication.
Это и есть причина, по которой DBA-команда не торопилась failback’ать. Технический failback - команда ALTER AVAILABILITY GROUP FAILOVER, минуты. Реальный failback - убедиться что:
- Сеть стабильна. Сделали трассировку, дождались устранения root cause.
- На secondary за время работы не накопилось расхождений.
- Все плановые операции с базами завершены или прерваны контролируемо.
- Бизнес-сервисы готовы к новому переключению.
В нашем инциденте эти условия выполнены не были. Обвязка на secondary не приехала: SQL Agent Jobs не запускались, CDC оборвался, часть бизнес-функций крутилась с тихими дефектами. И DBA-команда вынуждена была разрешать накопленные расхождения до того, как переключаться обратно. 7,5 часов - не норма процесса, а прямое следствие того, что secondary не работала так, как должна. И в эти 7,5 часов система продолжала жить с теми же тихими дефектами, которые в выходной день никто не успел заметить. В рабочий день первый же отчёт по сверке показал бы расхождения, и инцидент быстро перестал бы быть тихим.
Дисциплина обвязки - не настройка, а процесс
Решение проблемы обвязки - не «один раз настроил и забыл», а постоянная операционная дисциплина:
- SQL Agent Jobs - синхронизировать через скрипты с проверкой. Job существует на обеих нодах одинаковый, но реально работает только когда нода в роли primary.
- Logins - регулярный sync либо contained users где возможно. На SQL Server 2022 - переходить на Contained AG (об этом ниже).
- Linked Servers - аудит, сверка между нодами раз в неделю плюс при каждом изменении.
- CDC - в SQL Server 2017+ есть workaround с capture-job на обеих репликах, но он хрупкий. Для критичных потоков - либо
dbatools, либо ручной мониторинг с алертами на расхождение. - Аудит расхождений - cron-скрипт, сверяющий
msdb.dbo.sysjobs,sys.server_principals,sys.serversмежду primary и всеми secondary. Алерт в monitoring если расхождение появилось - и это бизнес-критичный alert, не info. - Документированный change-process - все изменения в instance-level объекты идут через sync-pipeline, прямые правки на одной ноде запрещены.
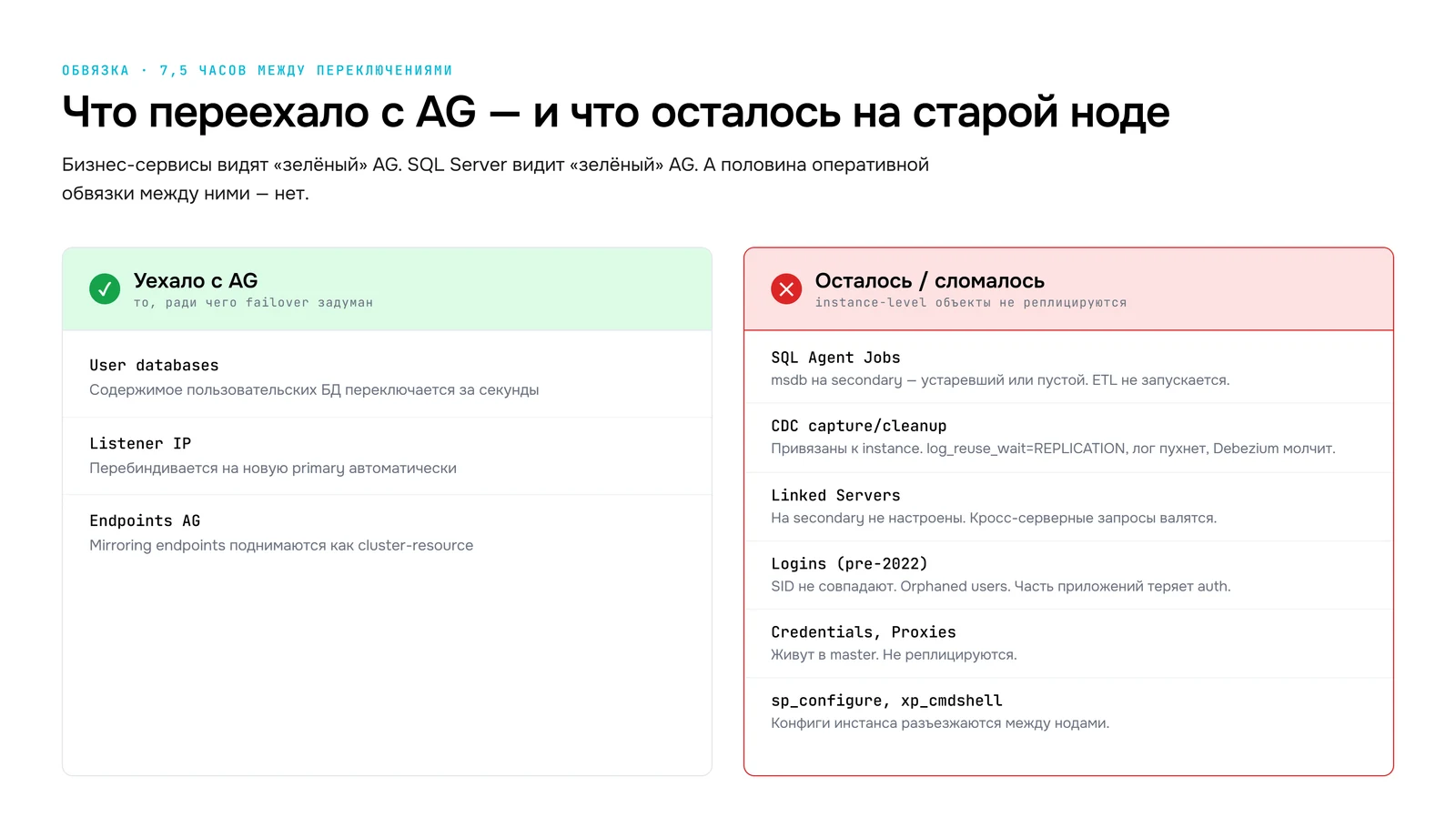
Без этой дисциплины ваша группа доступности - это не отказоустойчивая платформа, а просто база данных, умеющая красиво переключаться между узлами. Бизнес от этого ничего не получает.
Алерты сыпались. Только не туда, где могли бы помочь
У читателя может возникнуть резонный вопрос: если обвязка ломалась, и в msdb валились джобы, в логах появлялись log_reuse_wait_desc=REPLICATION и orphaned-юзеры - почему никто не отреагировал? Мониторинг ведь был.
Был. И именно эта параллельная история - часть проблемы.
В современном production-окружении среднего и крупного предприятия стоит несколько систем мониторинга и сотни активных алертов. Zabbix или Prometheus на инфраструктуру, Datadog или SCOM на SQL Server, отдельные системы на бизнес-приложения. У каждой системы свой routing - кто получает уведомление, кто за него отвечает.
В нашем инциденте алерты по failed-джобам шли в группу поддержки бизнес-систем. Это правильный routing - джобы выполняют бизнес-логику, поддержка - их зона ответственности. Алерты по самому SQL Server и AG - в DBA-команду. Тоже правильно.
Что в этой схеме не предусмотрено: бизнес-джоб может фейлиться не по бизнес-причине, а по DBA-причине. После failover Job не нашёл объекта в msdb на новой primary - для бизнес-команды это выглядит как обычный «джоба X не отработала». Они проверяют: код джобы в порядке, целевая база доступна, входные данные есть. Эскалировать в воскресенье сами не торопятся - не критично.
DBA-команда в этот момент видит чистый AG: все реплики в SYNCHRONIZED, healthcheck зелёный, listener отвечает. С их стороны - всё хорошо.
Алерты сыпались. Только не туда, где их могли бы интерпретировать в контексте «failover испортил обвязку, и бизнес-джобы фейлятся как следствие». Между двумя командами не оказалось моста: ни автоматического (cross-correlation алертов), ни ручного (звонок в стиле «у нас тут странность, у вас за ночь ничего не двигалось?»).
Это - частный случай усталости от алертинга. За последние пять лет индустрия инвестировала колоссальные ресурсы в observability: метрики, дашборды, distributed tracing, log aggregation, alert routing. И параллельно создала ситуацию, в которой каждая команда тонет в собственном потоке уведомлений и фильтрует чужие. Алерт, который в идеале должен был зажечь красным во всём операционном центре, проходит через два-три фильтра и оседает в стопке «посмотрим в понедельник».
Технических решений у этой проблемы немного, и все они работают на одной задаче - создать тот единственный громкий алерт, ради которого нужно бежать.
Регулярные cross-team post-incident-review’ы - не только DBA разбирает инцидент, а вся цепочка: DBA, поддержка бизнес-систем, инфра, безопасность. Каждая команда узнаёт, как её алерт выглядел со стороны соседей, и из этого формируются новые корреляции на будущее.
Тренировки, в которых проверяется не только техническое восстановление, но и cross-team-коммуникация. Дёшево по сравнению с настоящим инцидентом.
Правильно работающий мониторинг устроен одним способом: если мир не рухнул, всё может подождать. Алерт - это сирена, при звуке которой инженер бросает воскресенье и идёт чинить. Среднего уровня нет. И чтобы сирена сработала именно тогда, когда нужно, она должна быть единственной в потоке - иначе её не отличить от ещё пятисот «critical» в день.
В нашем инциденте сирены не было. Технически алертов сыпалось полно: failed-джобы в группе поддержки бизнес-систем, чистые зелёные индикаторы AG у DBA-команды. Но ни один из них не звучал как «у вас сломалась обвязка после failover, бросайте всё и идите чинить». Не потому что команды глухие. А потому что сигнал о рассинхроне обвязки никто не свёл воедино в один громкий алерт. Каждый отдельный сигнал выглядел как обычный шум - и поэтому стал обычным шумом.
7,5 часов прошли тихо именно по этой причине. Мониторинг был выстроен под нормальную работу, не под cross-team-инцидент с участием обвязки AG. Мир в воскресенье действительно не рухнул, и по правилам нормального алертинга всё могло подождать. Беда в том, что у обвязки мир именно рухнул - просто об этом ни одна система не сказала вслух.
Что меняет Contained AG в SQL Server 2022
Microsoft признала проблему обвязки и в SQL Server 2022 представила Contained Availability Group. Идея простая: AG включает в себя не только user-databases, но и изолированные копии master и msdb на уровне самой группы. Logins, jobs, schedules, operators - failover’ятся вместе с AG.
Что Contained AG берёт автоматически:
- Logins, server-роли, server-permissions внутри AG
- Jobs, schedules, operators, alerts
- Credentials, proxies
Что Contained AG всё ещё требует ручной синхронизации:
- Linked Servers (живут в instance-level master, не в contained-master)
- xp_cmdshell конфиги,
sp_configure - SQLCLR-сборки в master
- SSIS catalog (отдельный AG для SSISDB или ручной sync)
- CDC - хрупкая комбинация со специфическими ограничениями
- Сертификаты на ОС-уровне, network paths для backup
Contained AG закрывает 60-70% обвязочных болей. Но не все. И что важнее - он создаёт новый класс проблем.
Инцидент 2: Contained AG AG-Tenant застрял в RESOLVING
В тот же день, после того же сетевого сбоя, на отдельном кластере с Contained AG случилось вот что:
- Failover отработал, Contained AG
AG-Tenant(SQL Server 2022) переехал наsrv-contained-01 - Когда восстановили сеть, попытались сделать failback - команда
ALTER AVAILABILITY GROUP ... FAILOVERпадала с ошибкой - Диагностика:
Get-ClusterResourceсообщил«cluster service is not running» - ClusSvc на
srv-contained-01был остановлен. Почему - отдельный вопрос (политика безопасности? обновление? ручная ошибка?)
После Start-Service ClusSvc AG автоматически вернулся в Online.
В обычном AG отсутствие ClusSvc приводит к тому, что узел не участвует в кластере, но базы данных на нём могут быть в состоянии RECOVERY и доступны для read-only локально. В Contained AG - AG не может принять role primary без работающего WSFC вообще, потому что contained-master зависит от cluster API.
Contained AG жёстко завязан на ClusSvc на каждом узле, где он развёрнут. Это новый failure mode:
- ClusSvc остановлен на одной ноде → Contained AG на этой ноде неработоспособен
- В логах:
<contained_master> skipping startup- и это штатное поведение, не ошибка SQL Server - Без знания этой особенности команда теряет часы на диагностику не там, где надо
Вывод: Contained AG - полезная фича, но не «супер фишка». Решает большую часть обвязочной боли, но добавляет новые зависимости. Команда по обслуживанию должна знать оба класса проблем.
Ночной паттерн: что делать, когда failover’ится «без причины»
В журналах того же кластера обнаружились три предыдущих сбоя ресурса AG-Production:
| Дата | Время | Паттерн |
|---|---|---|
| 01.12.2025 | 22:41-22:42 | Online → ProcessingFailure → DelayRestarting → Online |
| 10.01.2026 | 22:36-22:37 | То же |
| 17.01.2026 | 22:08-22:09 | То же |
Не сетевые инциденты. AG-ресурс падал и поднимался автоматически. Раз в месяц, в окно 22-23 часа. Что это?
Скорее всего - maintenance jobs превышали HEALTH_CHECK_TIMEOUT. Default health check timeout - 30 секунд. Если SQL Server в этот момент занят перестройкой индексов на большой таблице, обновлением статистики или бэкапом, он может отвечать медленнее обычного. WSFC видит «SQL не отвечает» и помечает ресурс как failed. DelayRestartingResource поднимает обратно через минуту. Бизнес узнаёт о сбое по утреннему отчёту - если узнаёт.
Решение в этом классе - развести два механизма:
-- Ослабить health check для maintenance windows
ALTER AVAILABILITY GROUP [AG-Production] MODIFY
HEALTH_CHECK_TIMEOUT = 90000; -- 90 секунд
-- Снизить уровень триггеров
ALTER AVAILABILITY GROUP [AG-Production] MODIFY
FAILURE_CONDITION_LEVEL = 2; -- только server unresponsive FAILURE_CONDITION_LEVEL = 2 менее агрессивен, чем default 3. Не реагирует на «critical SQL errors», только на «SQL Server unresponsive». Для типичного prod это сильно снижает false-positive failover’ы, но часто, вокруг этого решения много споров и оно заслуживает отдельного обсуждения.
И параллельно - разнести обслуживание баз по времени между primary и secondary. Если index rebuild идёт ночью на primary, на secondary в это же время не должны крутиться тяжёлые отчёты или бэкапы.
Когда автоматический failover оправдан, а когда вреден
Главный архитектурный вопрос: нужен ли вообще быстрый автоматический failover при сетевом сбое?
Мой ответ - в большинстве сценариев сетевого сбоя не нужен и часто вреден. Failover полезен только когда:
- Авария локализована на primary (диск, hardware, SQL crash), а сеть и secondary живы
- Авария долгая (больше 5-10 минут), self-healing маловероятен
- Обвязка синхронизирована, и failover не приведёт к скрытому простою бизнеса
В нашем инциденте ни одно из условий не выполнялось. Сеть и нода с witness - не локализованная авария. Несколько минут blip’а - не повод для переключения. А обвязка не была синхронизирована, и поэтому failover конвертировал технический сбой в 7,5 часов «вроде бы» работающего сервиса с тихо накапливающимися расхождениями. Спасло только то, что был выходной.
Правильная архитектурная позиция:
Failover оправдан только при доказанной неисправности самого primary - не при потере его сетевой видимости.
Конкретные следствия:
- Network heartbeat threshold - длинный (5+ минут). Сеть мигнула - ждём.
- AG health check timeout - короткий (30-60 секунд). SQL crash - быстро ловим.
FAILURE_CONDITION_LEVEL = 2- менее агрессивный.- Cross-DC autofailover отключён - только manual.
- Witness в третьем сегменте - Cloud Witness или FSW в DR.
- Алерты приоритетнее failover’ов - сеть упала → пейджим DBA, не triggerим переключение.
И главное - контракт с бизнесом. Если в SLA написан RTO 1 минута, а DBA при этом всё равно делает manual review перед failback’ом, надо менять либо SLA, либо процесс. Иначе формальный SLA не отражает реальное состояние HA.
Чек-лист зрелости AlwaysOn AG в 2026
Прежде чем включить автоматический failover в production, ответьте «да» на каждый из этих 13 пунктов:
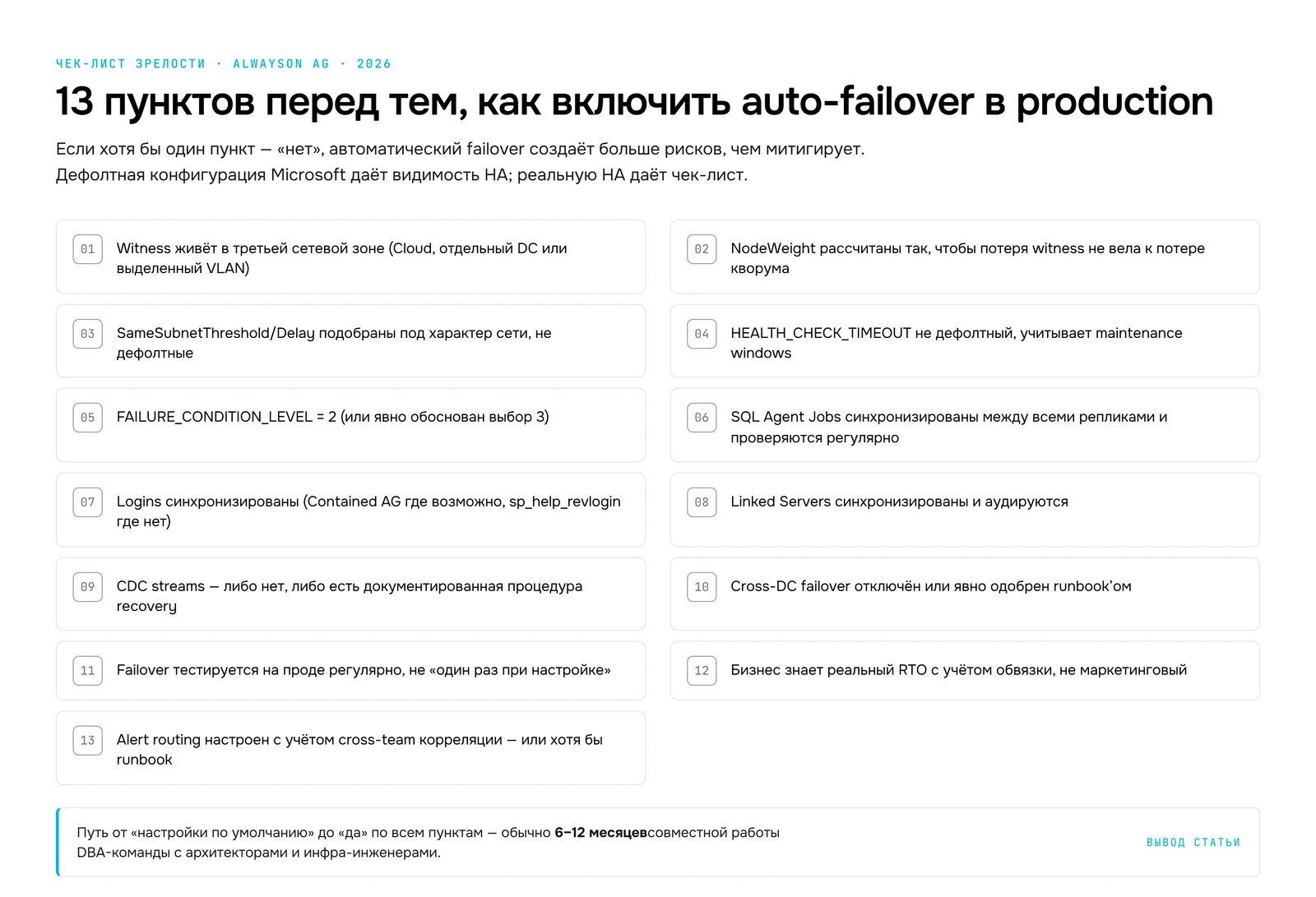
- Witness живёт в третьей сетевой зоне (Cloud, отдельный DC или выделенный VLAN)
NodeWeightрассчитаны так, чтобы потеря witness не вела к потере кворумаSameSubnetThreshold/Delayподобраны под характер вашей сети, не дефолтныеHEALTH_CHECK_TIMEOUTне дефолтный, учитывает maintenance windowsFAILURE_CONDITION_LEVEL = 2(или явно обоснован выбор3)- SQL Agent Jobs синхронизированы между всеми репликами и проверяются регулярно
- Logins синхронизированы (Contained AG где возможно,
sp_help_revloginгде нет) - Linked Servers синхронизированы и аудируются
- CDC streams - либо нет, либо есть документированная процедура recovery после failover
- Cross-DC failover отключён или явно одобрен runbook’ом для каждого случая
- Failover тестируется на проде регулярно, не «один раз при настройке»
- Бизнес знает реальный RTO с учётом обвязки, не маркетинговый
- Alert routing настроен с учётом cross-team корреляции: алерт по бизнес-джобе автоматически связан со state AG, и обратно. Или хотя бы прописан runbook на проверку «не было ли failover’а» при подозрительных алертах
Если хотя бы один пункт - «нет», ваш автоматический failover создаёт больше рисков, чем митигирует.
Вывод
Автоматический failover в AlwaysOn - не настройка, которую включают или выключают. Это операционная зрелость, состоящая из дизайна кворума, дисциплины обвязки, понимания четырёх триггеров и согласованного с бизнесом RTO.
Дефолтная конфигурация Microsoft даёт вам видимость High Availability (HA). Реальная High Availability появляется тогда, когда вы прошли по чек-листу выше и можете на каждый пункт ответить «да, проверено, тестировано, мониторится». В большинстве компаний этот путь занимает 6-12 месяцев работы DBA-команды совместно с архитекторами и инфра-инженерами.
Если вы не готовы инвестировать в эту зрелость - то ваш RTO в реальности равен «время на выход дежурного DBA на связь + время на ручной анализ + ручной failback». Что обычно превышает 2-4 часа. И это нормально, если так и записано в SLA с бизнесом.
Что ненормально - это когда в SLA написано «RTO 30 секунд», а в production эти 30 секунд означают «secondary поднялась за 30 секунд, но обвязка не приехала, и следующие 7,5 часов часть бизнес-функций работает с тихими дефектами, которые могут быть замечены далеко не сразу».
И главный совет, который я могу дать на основе этого инцидента: если вам повезло, и серьёзный сбой обвязки случился в нерабочий день, не относитесь к этому как к «проскочили». Используйте подаренное время как урок. В рабочий день у вас не было бы 7,5 часов на спокойный разбор. Не было бы возможности вернуться к работе без давления реального простоя. Такие инциденты бесплатно обнажают то, что в другой день обнажилось бы дорого.
Если у вас есть похожий кейс - пишите @maxpiter или используйте бот @warpd_dataing_bot. Разбираем такие инциденты в формате аудита AG-конфигурации - от witness placement до синхронизации обвязки.
Сайт: warpd.ru · Telegram-канал: @warp_data

Основатель WARP.D. 30 лет в отрасли - от администрирования SQL Server до архитектуры data-платформ на открытом стеке. Банки, инвестиционные компании, федеральный ритейл.